Intelligenza Artificiale
Apprendimento Supervisionato vs. Non Supervisionato
Due modi di imparare per le macchine
Introduzione: Due Modi di Imparare per le Macchine (pensanti)
L’apprendimento automatico, o machine learning, è la scienza che permette ai computer di imparare dai dati senza essere programmati in modo esplicito.
È una tecnologia che, spesso senza che ce ne rendiamo conto, usiamo decine di volte ogni giorno. Ma come avviene il processo di apprendimento? Esistono due approcci principali attraverso i cui le macchine apprendo: l’apprendimento supervisionato e l’apprendimento non supervisionato.
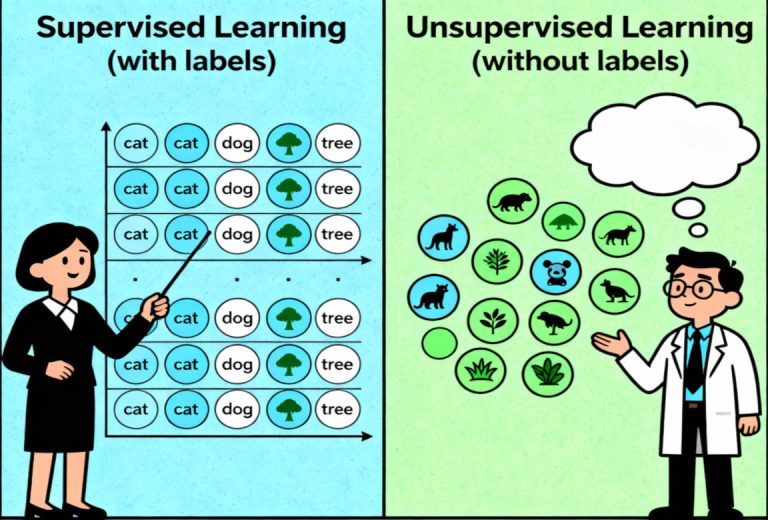
1. Apprendimento Supervisionato: Imparare con un Insegnante
1.1 Il Concetto Fondamentale
L’apprendimento supervisionato può essere paragonato a uno studente che impara con l’aiuto di un “insegnante”. In questa analogia, il lavoro dell’insegnante è fornire al computer dei dati di addestramento che contengono già le “risposte corrette”.
La chiave di questo approccio è l’uso di dati etichettati. Ciò significa che per ogni dato di input (indicato come X), viene fornito il corrispondente output corretto (indicato come Y).
L’obiettivo dell’algoritmo è imparare la relazione che mappa gli input agli output, in modo da poter prevedere l’output corretto per nuovi dati.
1.2 Il Processo: Step by Step
Il processo di apprendimento supervisionato può essere riassunto nei seguenti passaggi:
1 Raccolta Dati: Si parte da un set di dati che contiene coppie di input (X) e output corretti (Y). Ad esempio, un set di dati sui prezzi delle case potrebbe contenere la dimensione di ogni casa (X) e il suo prezzo di vendita effettivo (Y).
2 Addestramento: L’algoritmo analizza questi esempi per identificare una relazione, o “modello”, tra gli input X e gli output Y.
3 Previsione: Una volta addestrato, il modello è pronto. Può ricevere un nuovo input X che non ha mai visto prima (come la dimensione di una nuova casa) e produrre una previsione (Y-stimato) per il suo output.
1.3 Tipi di Apprendimento Supervisionato
Esistono due tipi principali di problemi risolti dall’apprendimento supervisionato:
- Regressione: Prevedere un Numero.
La regressione si utilizza quando l’obiettivo è prevedere un valore numerico continuo, come 200.000 €, 253.000 € o qualsiasi altro numero intermedio.
Esempio: Prevedere il prezzo di una casa.
L’algoritmo impara da un set di dati di case con dimensioni e prezzi noti. In seguito, può prevedere un prezzo specifico per una nuova casa di cui si conosce solo la dimensione. - Classificazione: Prevedere una Categoria.
La classificazione si utilizza quando l’obiettivo è assegnare un input a una categoria specifica, scelta da un insieme limitato e finito di opzioni.
Esempio: Diagnosticare un tumore.
Le categorie di output sono solo due: “benigno” (rappresentato dal valore 0) o “maligno” (rappresentato dal valore 1). A differenza della regressione, l’algoritmo non può prevedere valori intermedi come 0.5 o 0.7; la scelta è limitata alle categorie predefinite.
Ora che abbiamo sdoganato i concetti base dell’apprendimento supervisionato dobbiamo chiederci: ma cosa succede quando non abbiamo le “risposte corrette” con cui iniziare? È qui che entra in gioco l’apprendimento non supervisionato.
2. Apprendimento Non Supervisionato: Scoprire Strutture Nascoste
2.1 Le fondamenta
L’apprendimento non supervisionato può essere visto come il lavoro di un esploratore che deve dare un senso a un territorio sconosciuto. In questo caso, il computer riceve dati non etichettati, ovvero solo gli input (X) senza alcuna risposta corretta (Y) associata.
L’obiettivo non è fare una previsione specifica, ma trovare autonomamente schemi, raggruppamenti o “strutture interessanti” all’interno dei dati. L’algoritmo deve scoprire da solo le relazioni nascoste.
2.2 Il Processo: Step by Step
Ecco come si svolge il processo di apprendimento non supervisionato:
- Raccolta Dati: Si parte da un set di dati che contiene solo input (X), senza etichette di output.
- Analisi: L’algoritmo esamina i dati per identificare somiglianze, differenze o schemi ricorrenti.
- Raggruppamento (Clustering): L’algoritmo organizza i dati in “cluster” o segmenti omogenei in base alle strutture che ha identificato autonomamente.
2.3 Esempio Pratico: Raggruppare Articoli di Notizie
Un eccellente esempio di apprendimento non supervisionato è il clustering, utilizzato da servizi come Google News.
- L’algoritmo analizza centinaia di migliaia di articoli di notizie pubblicati online ogni giorno.
- Senza che nessuno gli abbia detto in anticipo quali sono gli argomenti del giorno, identifica articoli che utilizzano parole chiave simili (es. “rapina”, “incidente”, “tennis”).
- Li raggruppa automaticamente in cluster, presentando all’utente notizie correlate sullo stesso argomento.
Questo compito deve essere non supervisionato. Gli argomenti delle notizie cambiano ogni giorno e il volume di articoli è così vasto che sarebbe impossibile per delle persone etichettare tutto in tempo reale.
Altri esempi pratici includono l’analisi di dati genetici per trovare gruppi di individui con caratteristiche simili o la segmentazione dei clienti di un’azienda in diversi gruppi di mercato per personalizzare le offerte.
Ora che abbiamo esplorato i entrambi gli approcci in maniera distinta, mettiamoli a confronto per evidenziare le loro differenze chiave.
3. Confronto Diretto: Le Differenze fondamentali
| Caratteristica | Apprendimento Supervisionato | Apprendimento Non Supervisionato |
|---|---|---|
| Dati di Input | Dati etichettati (coppie di input X e output Y) | Dati non etichettati (solo input X) |
| Obiettivo Principale | Prevedere un output corretto | Trovare strutture e schemi nascosti nei dati |
| “Risposte Corrette” | L’algoritmo impara dalle risposte fornite in anticipo | L’algoritmo deve scoprire le “risposte” (i gruppi) da solo |
| Esempi Tipici | Previsione dei prezzi delle case, Filtro antispam (classificazione di email come ‘spam’ o ‘non spam’), diagnosi medica | Raggruppamento di articoli di notizie, segmentazione del mercato, analisi genetica |
4. Conclusione: Quale Approccio Scegliere?
La scelta tra apprendimento supervisionato e non supervisionato dipende interamente dalla natura del problema che si vuole risolvere e, soprattutto, dal tipo di dati a disposizione. Se si dispone di un set di dati con risposte corrette già note (dati etichettati) e l’obiettivo è fare previsioni, l’apprendimento supervisionato è la scelta giusta.
Se, diversamente, si dispone di dati grezzi senza etichette e l’obiettivo è esplorarli per scoprire intuizioni e raggruppamenti naturali, l’apprendimento non supervisionato è lo strumento più adatto.
Entrambi gli approcci sono strumenti potenti e complementari nel vasto campo del machine learning, e insieme costituiscono il motore invisibile dietro a molte delle tecnologie che, come abbiamo visto all’inizio, usiamo decine di volte ogni giorno.